
Understanding the Normal Distribution for Real
Building intuition by dissecting the monster formula

In this post, I build intuitions on why the Normal distribution is the way it is.
The usual probability theory course goes like this. First, you are presented with intuitive and relatively simple concepts. It’s all about real-life things like coin tosses, balls in urns, rabbits in cages, and so on.
Next, you are hit with this monster:
Suddenly there are no more coins or urns. You are told this is the probability density function of the Normal distribution, it is a really important distribution and the plot looks like a bell. Apart from that you are on your own.
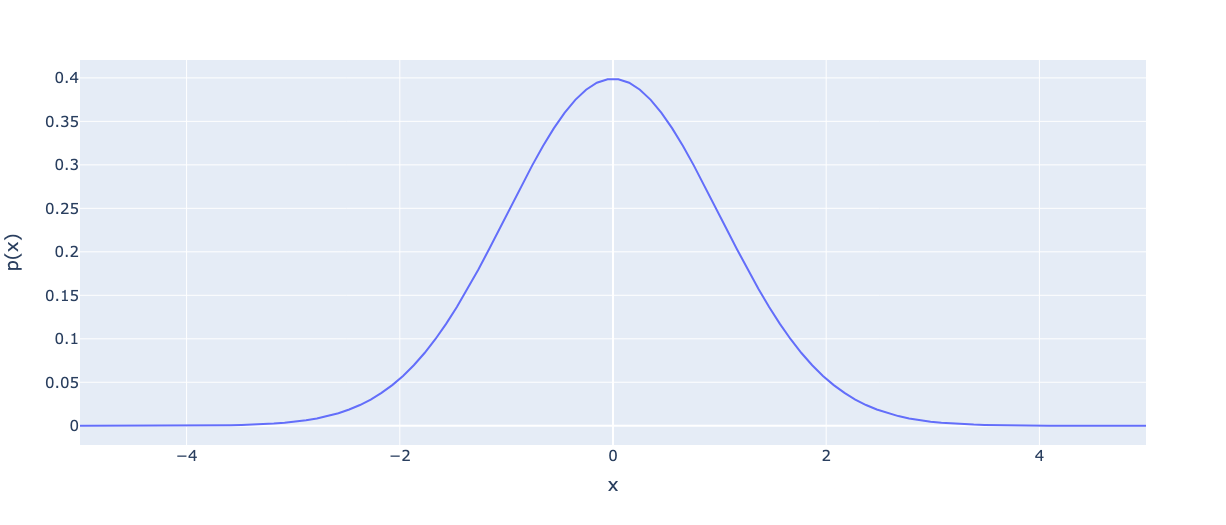
But what is it? Why the exponent? Why the minus? Why divide by 2 sigma squared? Where did the Pi come from?
More importantly: where did the coins, balls, urns, and rabbits go? What happened to intuitive explanations?
Each formula represents an idea. In this post, we will explore the Normal distribution to find what it represents. Finally, we will derive the scary probability density function. I will show that despite the intimidating look the Normal distribution is still about coins, urns, and other real-life things.
Dissecting the monster
First of all, we will understand the formula by cutting the monster apart and inspecting each piece.
X minus mu
First target:
mu is a parameter, the mean of the distribution.
Let’s plot this as a function of x.

We see a parabola. It looks like a bell shape but flipped. Also notice: the y-axis is arbitrary, not within [0, 1] range.
First, notice that the further x is from the mean, the larger the function. Consequently the lower the probability.
Second, the square makes sure we treat negative and positive values the same. It makes the bell shape symmetric.
The idea: mu defines the location of the bell peak, and the distribution is symmetric.
Let’s add the minus and plot the result:

Finally, a bell shape! But the y values are negative. Surely we can’t have negative probabilities.
What happens if we change mu?

Takeaway: Changing mu moves the bell peak to another spot.
Let’s add the next piece:
Here sigma is another distribution parameter: the standard deviation. Sigma squared is variance. What does it do for our distribution?
Let’s plot it:

The idea: the denominator is there to adjust the speed of change as we move away from the mean. Smaller sigmas make narrow bell shapes.
We can think of sigma as a measure of uncertainty. Small sigmas indicate that the mean value is more likely. Larger sigmas distribute the probability across a wider range.
The sigma is squared to indicate: uncertainty increases quadratically (fast), not linearly (slow). In other words, a little variation in data changes the bell curve a lot.
The exponent
Great, we have a bell curve. But it does not look like a probability distribution. For it to be a distribution the outputs must be within [0, 1] and sum to 1. This is where the exponent comes in.
Let’s plot the exponent e(x) around zero:

Observe: the exponent maps any negative input to a value between 0 and 1. In our case, the argument of exp is always negative.
Back to plotting:

Great! Now all the values are between [0, 1] and we have the bell curve we need. We are done.
Normalizing
Actually, no. This is a fine bell curve, but the values do not sum to 1. The peak alone is almost 1.
How do we make it sum to 1? Normalize!
How would you normalize a sequence of numbers like this: [0, 1, 2, 3, 4]? Easy: divide by the sum.
In our case, the function is not just a simple sequence of numbers. It’s continuous. However, same idea applies. Let’s integrate the function to get the sum.
Now that we have the sum, let’s divide the function by it:
Finally, we have reassembled all the parts to obtain the Normal distribution.
For details on computing the integral, I recommend this video:
The Binomial connection
The Normal is tightly related to the Binomial distribution. Let’s make a detour to examine the Binomial. It will help us get a full understanding of the Normal.
Imagine you have a website and you are about to run an ad campaign targeting 100 people. You know your conversion rate: 10%. What is the probability that exactly 5 people sign up? How many people do you expect to sign up?
Let’s model each website visitor by a coin toss. They either sign up with probability p=0.1 or don’t. This can be described by the Bernoulli(n, p) distribution which has the following probability mass function:
The idea: it’s a coin toss, there are two possible outcomes and you get heads with probability p.
This distribution allows you to answer questions like “What is the probability of heads for this coin?” or, more practically, “What is the probability a user will subscribe to my substack?”
We can sum multiple Bernoulli random variables and obtain the Binomial(k, p) distribution. It tells us the probability of getting k successes out of n independent Bernoulli trials with probability p.
The Binomial distribution aggregates all the independent trials to answer new questions: “What is the probability of getting 3 heads out of 3 tosses?” or “How many users can we expect to sign up?”
Here’s the Binomial distribution PMF:
The Binomial coefficient is there to account for many ways for k people to sign up. For example, given four visitors Alice, Bob, Charlie, and Emma there are six ways for two of them to sign up.
Let’s plug in our values to find the probability of exactly five people signing up: n = 100, k = 5, and p = 0.1.
The expected number of sign-ups among 5 users is simply n times p which equals 3.387. We can also get the probability of getting at least 5 sign-ups by summing over k>=5 and then we get 0.94242.
Now let’s take a look at what happens as the number of trials grows.

Observe: the resulting PMF seems to approach the familiar bell shape of the Normal distribution as n grows.
It turns out that the Normal distribution is a limiting case of the Binomial distribution. The Binomial answers this question: how likely is it to get k heads out of n coin tosses? The Normal distribution has the same idea, except it provides an approximate result.
We are interested in this approximation because computing Binomial coefficients for large values is computationally expensive. The factorials in the formula are the biggest problem. For example, for n=100, k=5 the binomial coefficient equals 75,287,520. That’s a lot of expensive computing, especially if you need to sum over many k.
Instead of computing the Binomial PDF, we can approximate it by computing the Normal distribution PMF. It is much faster: it only requires plugging some numbers into a formula. This approach is often used in surveys.
The core idea of the Normal distribution: the number of successes in a large number of independent yes-or-no trials is distributed symmetrically around the mean, with the shape of the distribution described by the Gaussian function.
Hopefully, now the Normal distribution PMF is no longer just a scary formula in a vacuum. It is still about coin tosses and real-life stuff.
Deriving the Gaussian
Why specifically this function? We will have to derive the Normal distribution PMF to answer this question. There are multiple ways to do that, but we will use our knowledge that the Normal it’s a limiting case of the Binomial distribution. I will only outline the main steps, as the details of derivation are quite long, but you can find a full derivation in this article.
Adding more nuance: Normal is a limiting case of Binomial as long as p is not very small and this holds:
If this does not hold we get Poisson distribution, which is also cool, but out of the scope of this post.
Remember the Binomial PMF. Suppose we have a sequence of Bernoulli trials, each with a probability of success p, and we repeat this experiment n times. Let X be the number of successes in the n trials. Then X has a binomial distribution with parameters n and p. The probability mass function of X is given by:
The heaviest part is the factorial. Let’s use Stirling’s approximation to compute it factorials faster:
Substituting it into our Binomial coefficient we get:
This might look scary, but in fact, it is just a substitution and some rearrangement of terms.
Substituting this approximation into the binomial distribution PDF, we get:
This is the probability density function of a normal distribution with mean equal to np and sigma squared equal to npq:
Takeaway: the Gaussian appears when we replace the factorials computations in Binomial with approximations.
Conclusion
We have dissected the Normal distribution in its components, explored the connection between the Binomial and the Normal, and finally derived the Normal PDF. Hopefully, it’s now less of a mysterious monster to you and more of a beautiful way of describing phenomena of the real world.
You can find for the plots in this collab.
Amazing work. I think it's very helpful for people who have studied probability theory at university, but it wasn't quite clear how to use it and what it is in general, articles like this are very helpful.
Awesome article, Boris! Thank you!
Would be glad to see posts about intuition on other distributions (Poisson's, Fisher's).